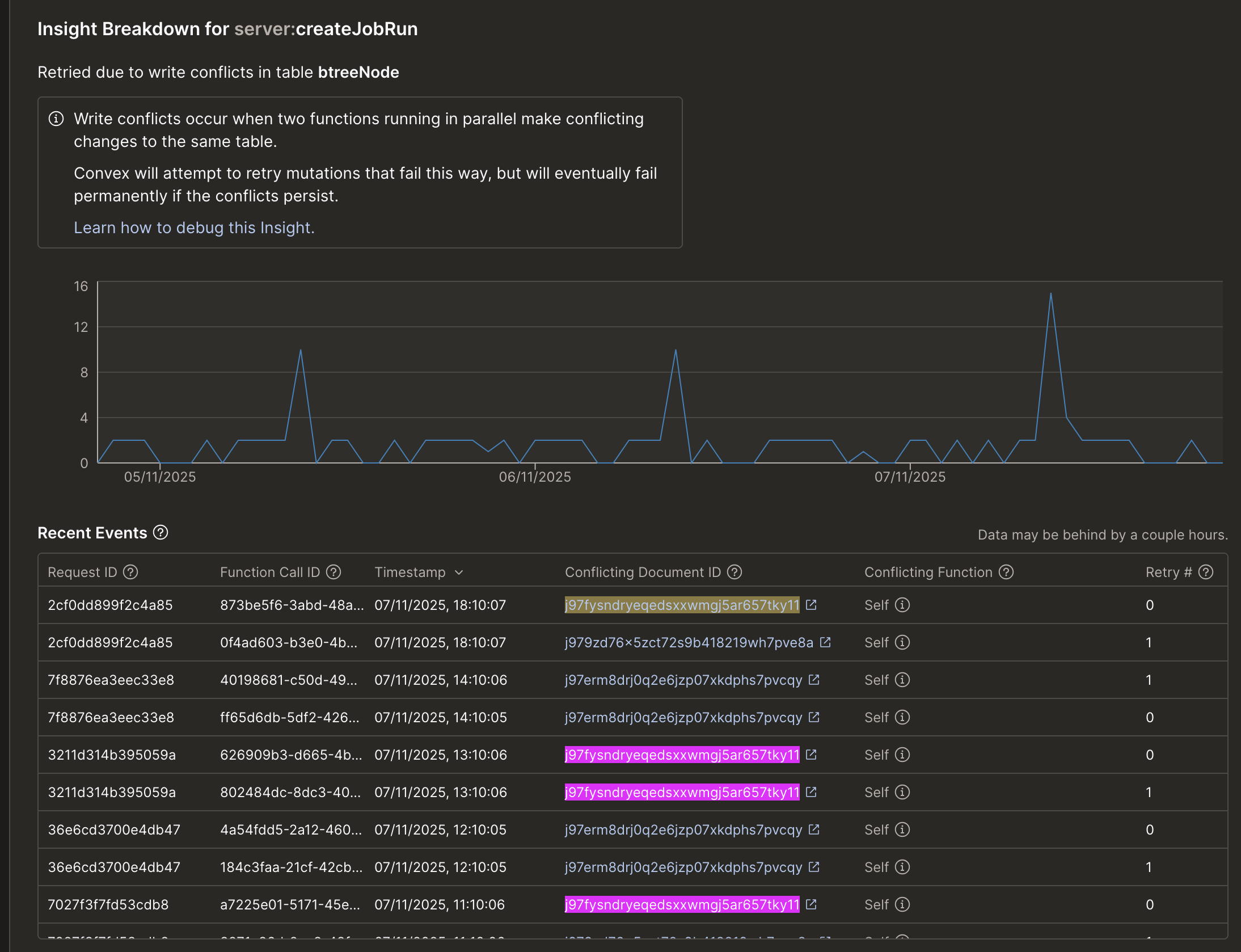
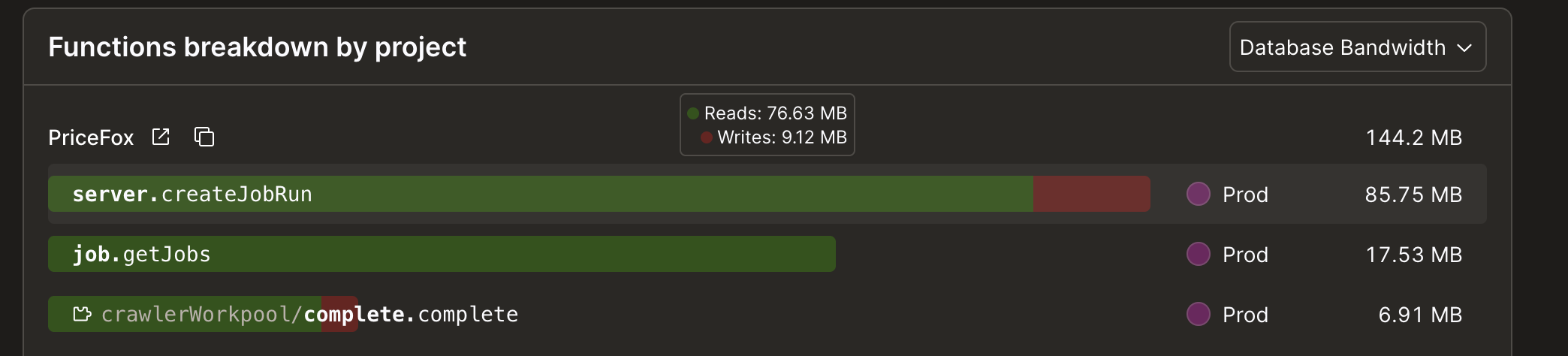
conflict write warnings, and excessive DB reads
I have lots of write warnings, and my function, which is only inserting, is causing high DB read bandwidth usage. This is the code for the function:



Hi @everyone with everything going on today I forgot to post on discord about our EU launch! We have a region in Dublin now! You can start using it immediately, even for folks on the free plan. https://news.convex.dev/we-finally-got-our-eu-visa/ Stay tuned for more regions but also stay tuned for more infra improvements where we improve latency for teams no matter where their servers are located. Just at the tip of the iceberg re all the optimizations we have lined up.
james · 4w ago

Hi @everyone happy Monday. Components Authoring [Challenge](https://www.convex.dev/components/challenge) updates! Meet the second batch of community-approved components **Firecrawl Scrape **- Scrape any URL and get clean markdown, HTML, screenshots, or structured JSON - with durable caching and reactive queries. https://www.convex.dev/components/firecrawl-scrape Built by: Gitmaxd **Durable Agents **- A Convex component for building durable AI agents with an async tool loop. https://www.convex.dev/components/durable-agents Built by: Siegfried **Convex Debouncer** - A server-side debouncing component for debouncing expensive operations like LLM calls, metrics computation, or any heavy processing that should only run after a period of inactivity. https://www.convex.dev/components/debouncer Built by: Ilya **DatabaseChat **- A Convex component for adding natural language database queries to your app. https://www.convex.dev/components/database-chat Built by: Nick **Transloadit** - A Convex component for creating Transloadit Assemblies, handling resumable uploads with status, and persisting status/results in Convex. https://www.convex.dev/components/transloadit Built by: Kvz **Loops** - A Convex component for integrating with Loops.so email marketing platform. https://www.convex.dev/components/loops Built by: Bobby The [challenge](https://www.convex.dev/components/challenge) is now ongoing, so keep building, and we'll keep rewarding. Thanks, everyone!
Wayne · 2mo ago

Hi everyone! Have you ever wanted to get your hands on some convex swag? Well you're in luck! We just launched our Convex swag store. Check it out here ---> https://store.convex.dev/
Liz C · 2mo ago